如何让你的机器人拥有持久化记忆
这是一个关于机器人学习的令人沮丧的事实:你的机器人在每个 episode 之间会遗忘一切。
在仿真环境中,你运行了 1,000 个抓取任务的 episode。第 #743 个 episode 发现 12.5N 的夹持力效果完美。第 #744 个 episode 从零开始。它不知道 30 秒前发生了什么。
这不是 bug — 这是大多数 RL 和启发式框架的工作方式。每个 episode 是独立的。智能体通过梯度更新模型权重来学习,而不是通过对过去经验的显式记忆。
但如果机器人能简单地记住呢?
问题:没有记忆的机器人
以 MuJoCo FetchPush 任务为例。一个机械臂需要将方块推到目标位置。使用启发式策略,基线成功率约为 42%。
机器人在每个 episode 中尝试不同的方法。有时推力过大。有时角度不对。有时运气好。但它从不积累这些经验。每个 episode 都是全新开始。
这是浪费的。一个旁观的人类会说:"你在第 #12 个 episode 就找到了正确的力度和角度 — 为什么又在尝试随机方法?"
解决方案:经验记忆
我们构建了 robotmem — 一个专为机器人设计的持久化记忆系统。不是为聊天机器人设计的(那是 Mem0 和 Zep 做的事)。而是为与真实世界交互的物理智能体设计的。
思路很简单:
- 每个 episode 结束后,存储发生了什么 — 使用的参数、采取的轨迹、是否成功或失败,以及空间上下文。
- 下一个 episode 开始前,通过语义搜索检索最相关的历史经验。
- 利用检索到的经验引导策略偏向之前有效的策略。
代码如下:
from robotmem import learn, recall
# 成功抓取后 — 存储参数 + 结构化上下文
learn(
insight="FetchPush: success, distance 0.012m, 28 steps, force=12.5N, angle=0.34",
context='{"task": {"success": true}, "spatial": {"target": [1.3, 0.7, 0.42]}, "params": {"force_peak": 12.5, "approach_angle": 0.34}}'
)
# 下一个 episode:之前什么有效?
memories = recall(
"push cube to target position",
context_filter={"task.success": True}
)
# 使用检索到的参数引导策略
for m in memories["memories"]:
print(m["content"], m["_rrf_score"])结果:成功率提升 +25%
我们在 MuJoCo FetchPush-v4 上进行了三阶段实验测试:
- 阶段 A(30 个 episode):基线启发式策略,无记忆。42% 成功率。
- 阶段 B(30 个 episode):同样的策略,但现在将经验存储到记忆中。53% 成功率。
- 阶段 C(30 个 episode):每个 episode 前,回忆过去成功的经验并融合到策略中。67% 成功率。
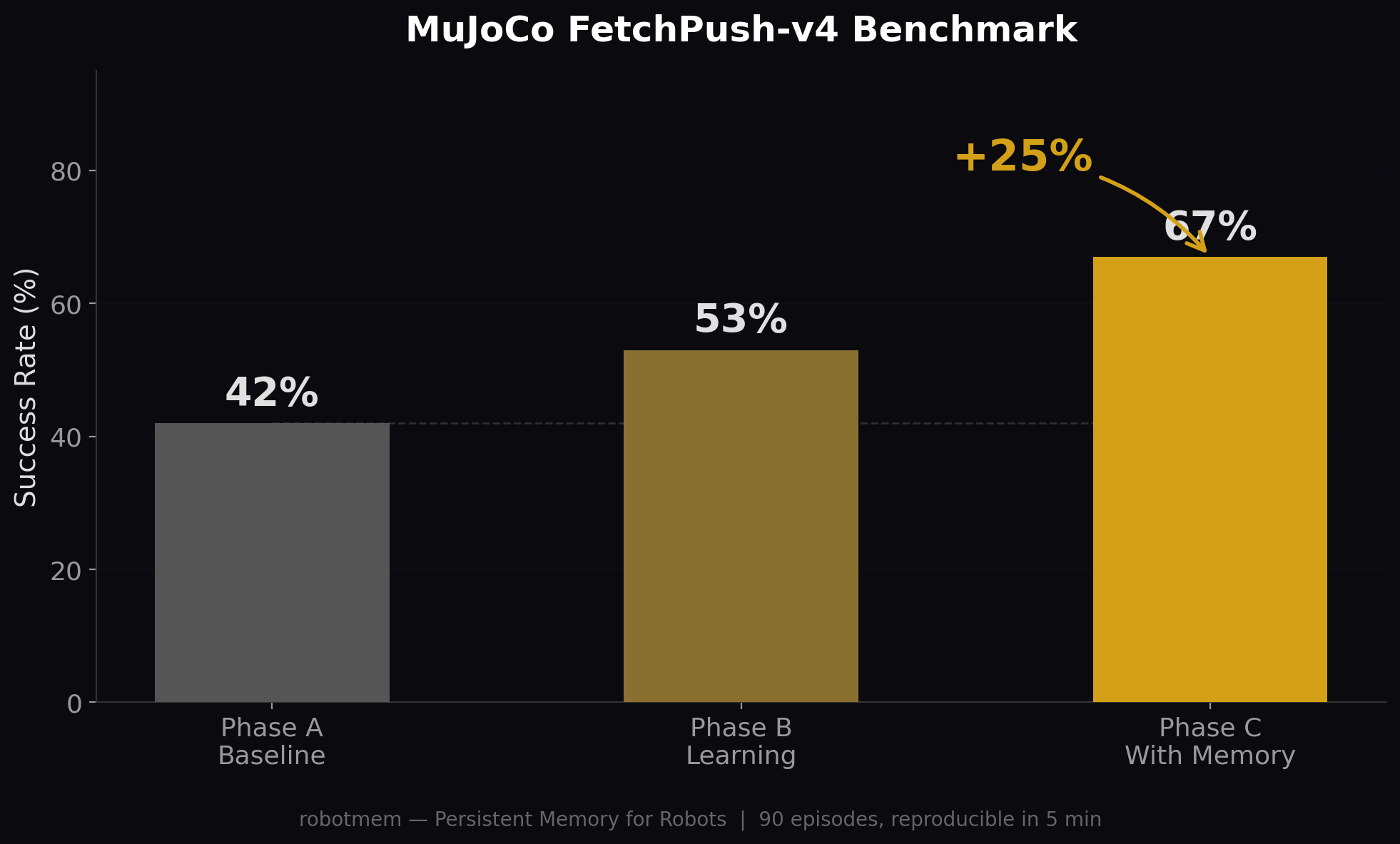
FetchPush-v4 基准测试。共 90 个 episode,5 分钟内可复现。
仅通过记住过去的经验,就实现了 +25 个百分点的提升(42% → 67%)。无需重新训练模型。无需架构更改。只靠记忆。
底层工作原理
robotmem 将经验存储在本地 SQLite 数据库中,提供三种搜索机制:
- BM25 全文搜索 — 关键词匹配("push"、"grasp"、"12.5N")
- 向量相似度搜索 — 语义匹配(即使用词不同,也能找到关于"抓取杯子"的经验)
- 倒数排名融合(RRF) — 结合两种排名以获得最佳结果
在搜索之上,robotmem 还提供:
- 5 种感知类型 — 视觉、触觉、听觉、本体感觉、程序性
- 结构化上下文过滤 — 通过 JSON 上下文查询"只显示成功的抓取"
- 空间排序 — "查找位置 [1.3, 0.7, 0.42] 附近的经验"
- 自动去重 — 图像使用 dHash,文本使用 Jaccard
- MCP 协议支持 — 将 robotmem 作为 AI 智能体(Claude 等)的工具使用
为什么不直接用 Mem0 或 Zep?
这是个合理的问题。区别如下:
| 特性 | robotmem | Mem0 / Zep / Letta |
|---|---|---|
| 目标用例 | 机器人 | 聊天机器人 |
| 多模态感知 | 5 种类型 | 仅文本 |
| 轨迹存储 | 支持 | 不支持 |
| 数值参数 | 支持 | 不支持 |
| 空间搜索 | 支持 | 不支持 |
| 离线能力 | 支持(本地 ONNX) | 需要云端 |
Mem0 擅长记住用户喜欢咖啡。robotmem 擅长记住在位置 [1.3, 0.7, 0.42] 处红色杯子的最佳夹持力为 12.5N。
5 分钟体验
你可以自己复现基准测试:
pip install robotmem gymnasium-robotics
cd examples/fetch_push
PYTHONPATH=../../src python demo.py或者尝试零依赖快速入门(无需 MuJoCo):
pip install robotmem
python -c "
from robotmem import learn, recall
learn(insight='grip_force=12.5N works best for red cups')
result = recall(query='grip force')
print(result)
"