How to Give Your Robot Persistent Memory
Here's a frustrating fact about robot learning: your robot forgets everything between episodes.
In simulation, you run 1,000 episodes of a grasping task. Episode #743 discovers that 12.5N of grip force works perfectly. Episode #744 starts from zero. It doesn't know what happened 30 seconds ago.
This isn't a bug — it's how most RL and heuristic frameworks work. Each episode is independent. The agent learns through gradient updates to model weights, not through explicit memory of past experiences.
But what if the robot could simply remember?
The Problem: Memoryless Robots
Consider a MuJoCo FetchPush task. A robotic arm needs to push a cube to a target position. With a heuristic policy, the baseline success rate is around 42%.
The robot tries different approaches each episode. Sometimes it pushes too hard. Sometimes the angle is wrong. Sometimes it gets lucky. But it never accumulates this experience. Each episode is a fresh start.
This is wasteful. A human watching would say: "You already figured out the right force and angle in episode #12 — why are you trying random things again?"
The Solution: Experience Memory
We built robotmem — a persistent memory system designed specifically for robots. Not for chatbots (that's what Mem0 and Zep do). For physical agents that interact with the real world.
The idea is simple:
- After each episode, store what happened — the parameters used, the trajectory taken, whether it succeeded or failed, and the spatial context.
- Before the next episode, retrieve the most relevant past experiences via semantic search.
- Use retrieved experiences to bias the policy toward strategies that worked before.
Here's what it looks like in code:
from robotmem import learn, recall
# After a successful grasp — store parameters + structured context
learn(
insight="FetchPush: success, distance 0.012m, 28 steps, force=12.5N, angle=0.34",
context='{"task": {"success": true}, "spatial": {"target": [1.3, 0.7, 0.42]}, "params": {"force_peak": 12.5, "approach_angle": 0.34}}'
)
# Next episode: what worked before?
memories = recall(
"push cube to target position",
context_filter={"task.success": True}
)
# Use retrieved parameters to guide the policy
for m in memories["memories"]:
print(m["content"], m["_rrf_score"])The Result: +25% Success Rate
We tested this on MuJoCo FetchPush-v4 with a three-phase experiment:
- Phase A (30 episodes): Baseline heuristic policy, no memory. 42% success.
- Phase B (30 episodes): Same policy, but now storing experiences to memory. 53% success.
- Phase C (30 episodes): Before each episode, recall successful past experiences and blend them into the policy. 67% success.
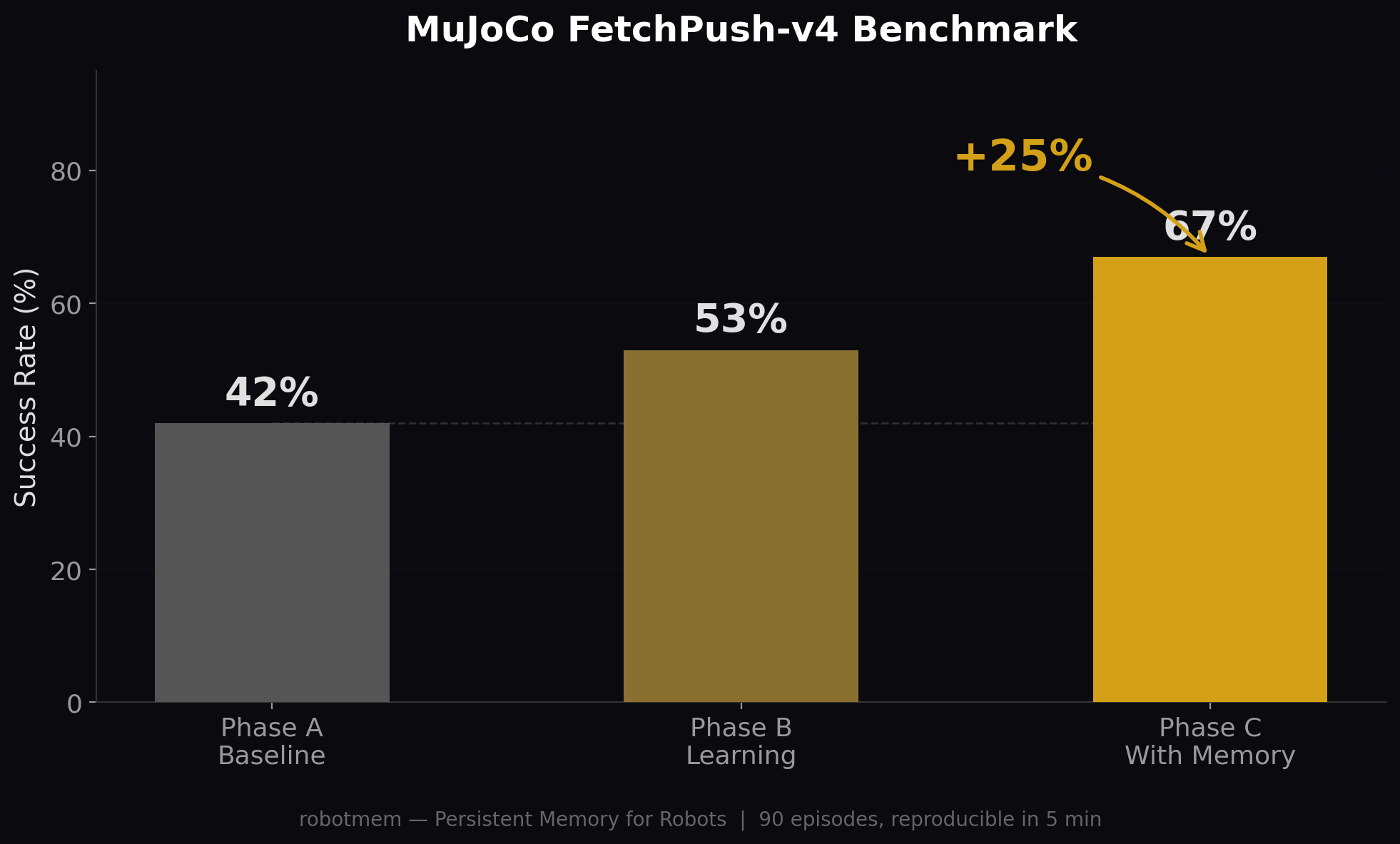
FetchPush-v4 benchmark. 90 episodes total, reproducible in 5 minutes.
That's a +25 percentage point improvement (42% → 67%) from simply remembering past experiences. No model retraining. No architecture changes. Just memory.
How It Works Under the Hood
robotmem stores experiences in a local SQLite database with three search mechanisms:
- BM25 full-text search — keyword matching ("push", "grasp", "12.5N")
- Vector similarity search — semantic matching (find experiences about "grasping cups" even if the words are different)
- Reciprocal Rank Fusion (RRF) — combines both rankings for best results
On top of search, robotmem provides:
- 5 perception types — visual, tactile, auditory, proprioceptive, procedural
- Structured context filtering — "show me only successful grasps" via JSON context queries
- Spatial sorting — "find experiences near position [1.3, 0.7, 0.42]"
- Auto-deduplication — dHash for images, Jaccard for text
- MCP protocol support — use robotmem as a tool for AI agents (Claude, etc.)
Why Not Just Use Mem0 or Zep?
Fair question. Here's the difference:
| Feature | robotmem | Mem0 / Zep / Letta |
|---|---|---|
| Target use case | Robots | Chatbots |
| Multi-modal perception | 5 types | Text only |
| Trajectory storage | Yes | No |
| Numeric parameters | Yes | No |
| Spatial search | Yes | No |
| Offline capable | Yes (local ONNX) | Cloud required |
Mem0 is excellent for remembering that a user likes coffee. robotmem is for remembering that 12.5N of grip force works for red cups at position [1.3, 0.7, 0.42].
Try It in 5 Minutes
You can reproduce the benchmark yourself:
pip install robotmem gymnasium-robotics
cd examples/fetch_push
PYTHONPATH=../../src python demo.pyOr try the zero-dependency quick start (no MuJoCo needed):
pip install robotmem
python -c "
from robotmem import learn, recall
learn(insight='grip_force=12.5N works best for red cups')
result = recall(query='grip force')
print(result)
"Give Your Robot Memory
Open source. Pure CPU. One install away.